Training
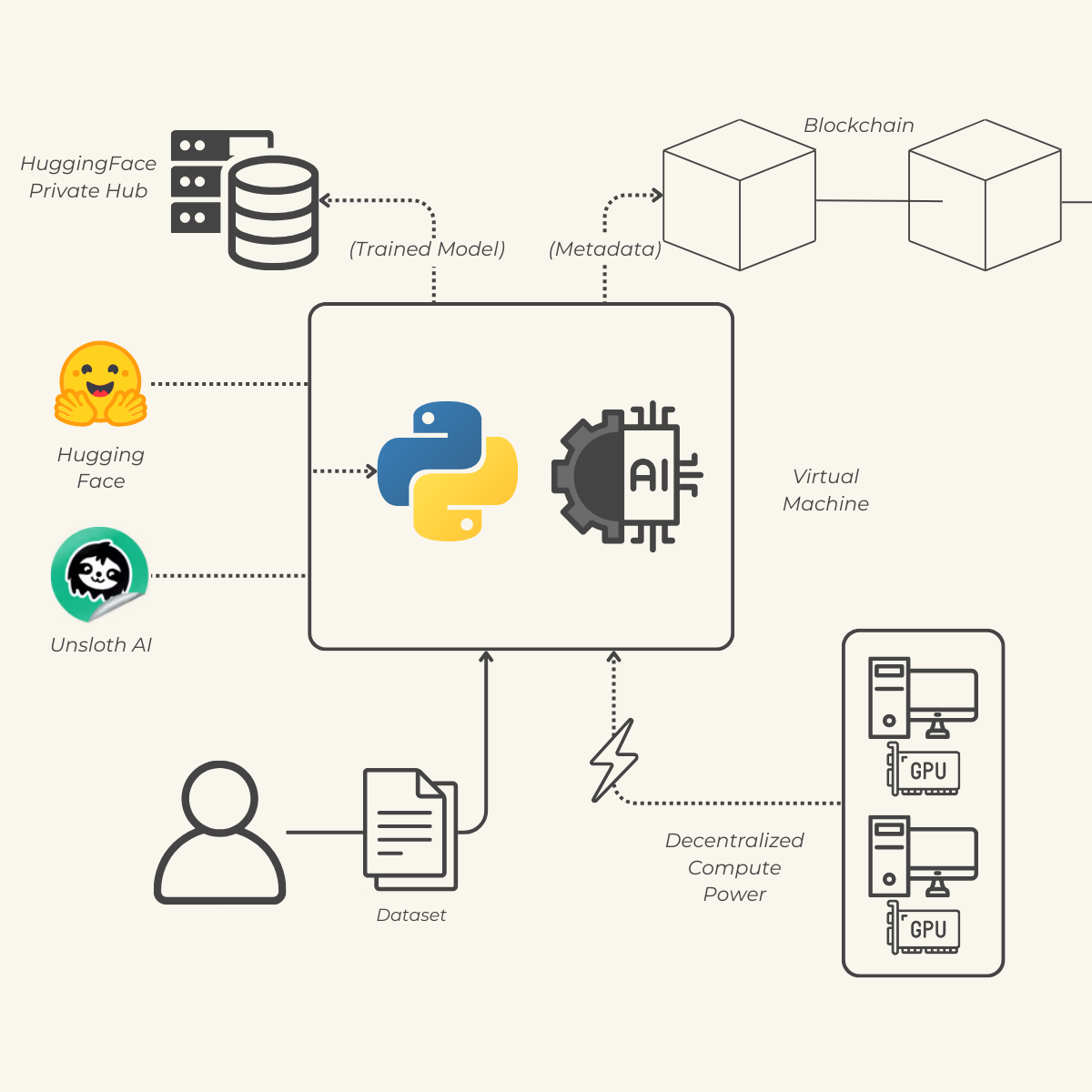
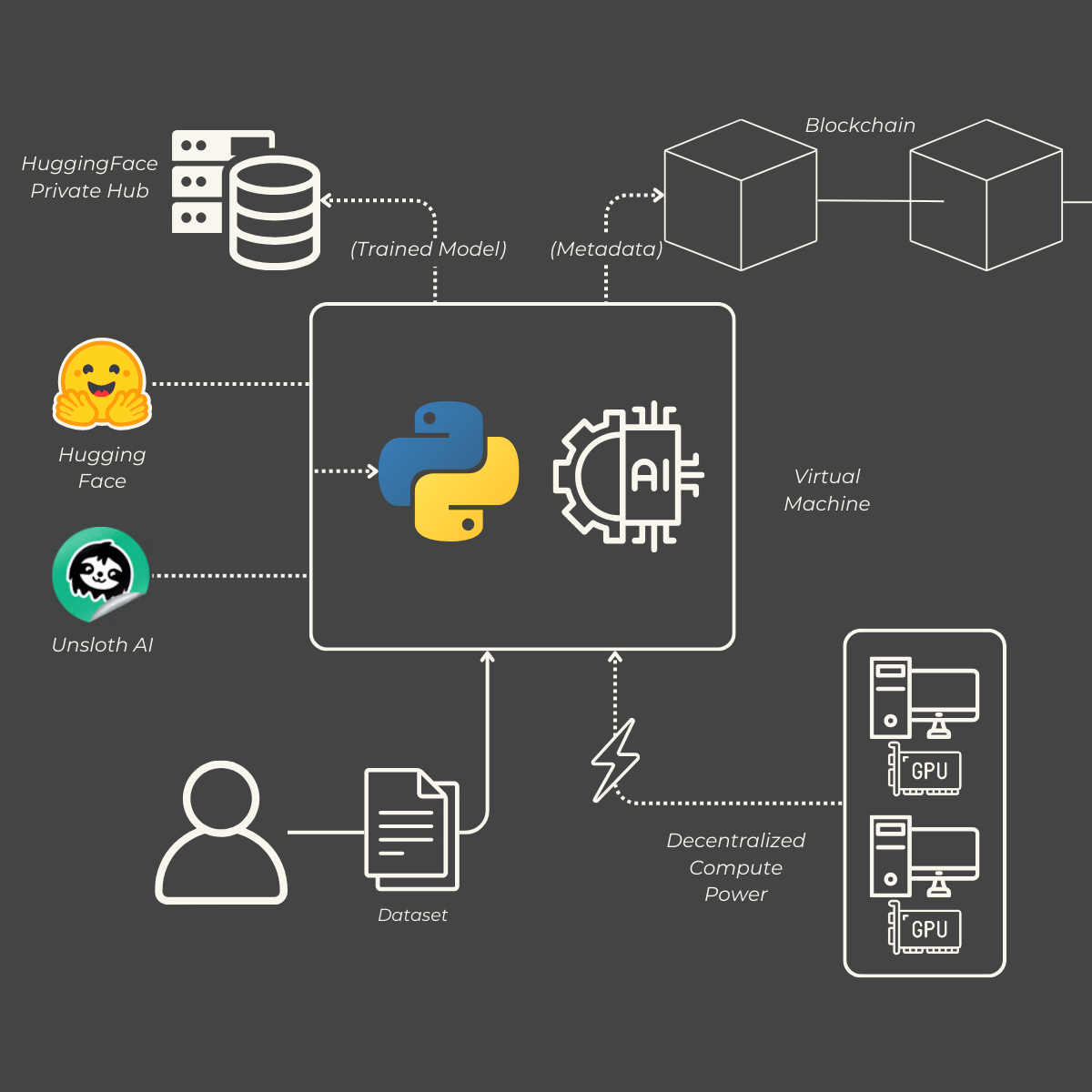
Virtual Machine Connection
Users can effortlessly connect to a virtual machine powered by a decentralized network of graphics cards. This setup ensures scalable and efficient computational resources, enabling high-performance training processes.
LLM Training
Our platform supports the training of large language models (LLMs) using frameworks from both UnslothAI and Hugging Face. Hugging Face provides an extensive hub of AI models, offering a robust foundation for model development. UnslothAI enhances this by applying quantization techniques, specifically QLora, to optimize and reduce model sizes without compromising performance.
Quantization and QLora
Quantization is a process that reduces the precision of the numbers used to represent a model's parameters, leading to smaller and faster models that require less computational power. QLora is a specialized quantization method that maintains the integrity and performance of large language models while significantly reducing their size. This allows for efficient deployment and scalability across various platforms.
Blockchain Recording
Transparency and traceability are paramount in our training process. Each step of the training workflow is meticulously recorded and stored on a blockchain. This immutable ledger ensures that all actions are verifiable and auditable, fostering trust and accountability throughout the model development lifecycle.
Metadata Storage
Each training request logs essential metadata, including:
- DateTime: The timestamp of when the training request was made.
- GPU Used: Details about the GPU resources utilized for the training.
- GPU Provider: The name or identifier of the provider supplying the GPU resources.
- GPU Price/Hour: The cost per hour for using the GPU resources.
- Model Trained: Information about the specific model that was trained and is being used for training.
- Model Parameters: Key parameters used for the model during training.
- Theme of Training: The primary focus or domain of the training process (e.g., natural language processing, image recognition).
- Time Training: The duration taken to train the model.
- Sender Address: The address initiating the training request.
Model Storage
Upon completion of the training process, the finalized model is securely saved to a user-specific address. Additionally, the model is made accessible outside the application via the Hugging Face Hub, allowing for easy integration and deployment across different environments and applications.
Customizable Python Script
To cater to diverse user needs, our platform provides a modifiable training script template directly on the interface. Users can tailor this script to fit their specific requirements, ensuring flexibility and control over the training parameters. For those who prefer, the platform also supports the use of custom templates or entirely bespoke training scripts.
Leveraging Decentralized Compute Power with PrimeIntellect
To harness decentralized computational power, we utilize PrimeIntellect, an aggregator of GPUs from various sources, both decentralized and centralized. This integration allows users to rent GPU resources at the most competitive market prices effortlessly, ensuring cost-effective and scalable training operations.
PrimeIntellect
PrimeIntellect is a company specializing in advanced artificial intelligence technologies, aiming to democratize access to AI. They focus on improving decentralized training processes and have recently deployed a decentralized GPU aggregator, optimizing the use of computational power.
Summary
Our comprehensive training infrastructure combines the robustness of Hugging Face's model hub with UnslothAI's advanced quantization techniques, all while ensuring transparency through blockchain recording. By leveraging PrimeIntellect's decentralized GPU aggregation, we provide a scalable, efficient, and cost-effective solution for training large language models tailored to user-specific needs.